
如何精准调整Debian MongoDB索引,实现查询速度的显著提升?
- 内容介绍
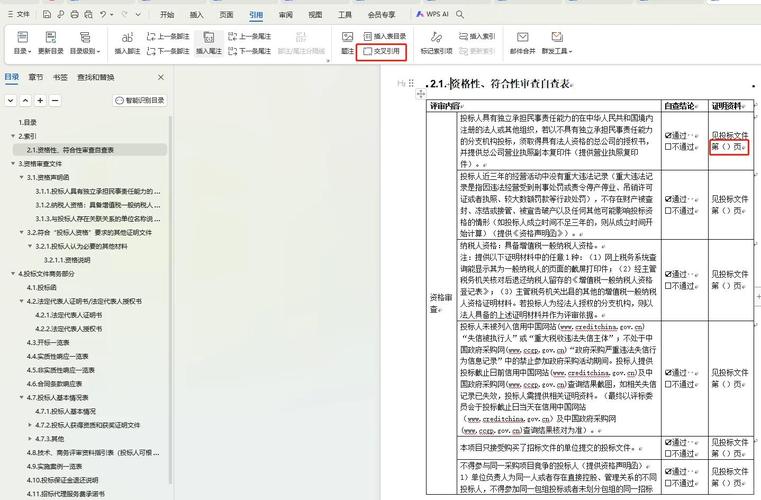
- 文章标签
- 相关推荐
序章:让Debian上的MongoDB焕发活力
当我们在繁忙的服务器机房里 听见硬盘嗡鸣与风扇呼呼的交响时往往会忽略一个细小却至关重要的细节——索引。它像是数据库的“血管”,决定着数据流动的畅通程度。今天 我要把这段看似枯燥的技术,揉进一杯暖心的咖啡里用温度和情感告诉你:只要精准调校索引,查询速度可以实现飞跃式提升!让我们一起为系统添砖加瓦,也为自己种下一棵技术的大树吧。
一、 索引基础:从概念到实践的桥梁
MongoDB 的索引本质上是 B‑Tree,它把键值映射到文档位置,从而省去全表扫描的苦工。想象一下 在浩瀚的数据海洋里你如果没有灯塔, 闹乌龙。 只能盲目划船;有了索引,就像装上了强大的探照灯,一眼就能锁定目标。
1. 单字段索引——最常用的速效药
薅羊毛。 对经常出现在查询过滤或排序中的字段创建单字段索引,是提升性能最直接的方法。比方说:
db.users.createIndex // 为邮箱字段建立升序索引
db.orders.createIndex // 为订单状态建立单字段索引
我好了。 记得:只为「常用」而非「有时候」创建索引, 否则会让写入变慢,磁盘空间也会被无情吞噬。
2. 复合索引——让多条件查询如虎添翼
我跟你交个底... 当查询一边涉及多个字段时 复合索引能够一次性覆盖全部条件,大幅削减扫描次数。关键在于字段顺序
- 选择性高的字段应放前面。
- 等值查询优先于范围查询。
- 排序需求若与过滤相同,可进一步提升效率。
示例:
// 假设我们经常按用户ID查找并根据创建时间倒序排列
db.activity.createIndex
二、 硬件加持:SSD 与系统调优不可或缺
瞎扯。 即便拥有完美的索引结构,如果底层存储仍是机械硬盘,那就像给跑车装上拖拉机发动机——再好的燃油也无济于事。SSD 的高速随机读写特性,使得 MongoDB 能够在毫秒级别完成大量 I/O 请求。
| 产品型号 | 顺序读写速率 | 耐久度 | 适配 Debian 推荐指数 |
|---|---|---|---|
| SATA Pro X500 | 550 / 520 | 600 TBW | ★★★★★ |
| M.2 NVMe UltraFast 970EVO+ | 3400 / 3000 | 1200 TBW | ★★★★★ |
| SAS Enterprise L30V4 | 2100 / 2000 | 2000 TBW | ★★★★☆ |
选购时请注意:
- I/O 队列深度要匹配业务并发量。
- NVM Express 驱动必须使用最新内核模块,以免出现兼容性警报。
- 务必开启磁盘 TRIM,以保持长期性能不衰退。
三、监控与诊断:让每一次查询都有据可循
干就完了! "慢查询日志" 是我们的第一把放大镜。打开后 你可以捕捉到所有超过阈值的操作:
# 在 mongod.conf 中启用慢查询
operationProfiling:
mode: slowOp
slowOpThresholdMs: 80
# 重启服务后即可记录
mongostat --host localhost --port 27017
mongotop --host localhost --port 27017
A "explain" 命令则像是手术刀,让我们看到每一步施行计划:
// 查看某条查询是否走了预期的复合索引
db.orders.find, status: "paid" }).explain
{
"queryPlanner": {
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"keyPattern": { "userId": 1, "status": 1 },
...
}
}
},
...
}
如果发现“COLLSCAN”仍然频繁出现,那就说明还有未被覆盖的热点,需要重新审视索引策略。哎呀,这时候真的会忍不住敲键盘“哎呦喂”,累并充实着。。
覆盖索引——一次读取即完成任务
当查询所需返回的字段全部包含在索引中时 MongoDB 可以直接从索引用来返回后来啊,而无需回表读取文档本体,这就是所谓的覆盖索引**,物超所值。。
// 假设我们只需要返回订单号和状态:
db.orders.find(
{ status: "shipped" },
{ _id: 0, orderNumber: 1, status: 1 }
).hint // 强制使用单字段索引用作覆盖
此时 explain 会显示仅有 IXSCAN, 无 FETCH 步骤,性能瞬间提升几倍!真是让人惊叹啊。四、 日常维护:让优化成果持久绽放
A. **定期重建碎片化严重的索引**
当大量删除或更新操作导致 B‑Tree 不平衡时可通过 { background:true }` 重建来恢复效率:
// 重建单字段索引
db.products.reIndex
B. **监控磁盘使用率**
SSD 的寿命虽长,但写入次数仍有限。使用 dstat -d -D sda -N sda -T total -c|grep sda|awk '{print $5}' ` 等工具实时监控写放大率,必要时进行分片或归档。
五、 实战检查清单
- 为所有经常用于过滤、排序、聚合管道首阶段的字段建立单字段或复合索引。
- 检查每个复合索引用途是否符合「高选择性→低选择性」原则。
- 确认关键业务查询均走到了覆盖索引或至少使用了预期的 IXSCAN。
- 启用慢查询日志并设置合理阈值,每日审计报告。
- 使用 SSD 替代机械硬盘,并开启 TRIM 与正确排队深度配置。
- 每月运行一次
.reIndex` 或者利用 MongoDB Atlas 自动化维护功能。
六、 :从细节中孕育大爱,让系统更健康
Cherished reader,你已经掌握了从设计、实现到监控的一整套优化思路。记住 每一次对 index 的微调,都像给数据库浇灌了一滴甘露,让它在 Debian 的坚实土壤中茁壮成长。正如我们倡导多生孩子、 多种树一样,多点耐心去观察、多点爱心去调校,你会看到查询响应时间从几百毫秒跌至十几毫秒,整个系统仿佛换了新装——轻盈且充满活力!赶紧把这些技巧付诸实践,让你的团队因速度而骄傲,也主要原因是你这颗执着改进的小星星而受益吧!🌱🚀
七、关联产品推荐
MongoDB 管理工具对比表格
工具名称
平台支持
核心功能
用户口碑
Mongo Express
Linu x / Windows / macOS
- 可视化浏览集合
- 简易 CRUD 操作
- 实时日志查看
★★★★☆
NoSQLBooster
Linu x / Windows / macOS
- 强大的 IntelliSense
- 聚合管道可视化
- 脚本自动化部署
★★★★★
Mongoku
Linu x / Windows / macOS
- 多标签页支持
- 导入/导出 CSV/JSON
- 支持 SSH 隧道连接
★★★☆☆
序章:让Debian上的MongoDB焕发活力
当我们在繁忙的服务器机房里 听见硬盘嗡鸣与风扇呼呼的交响时往往会忽略一个细小却至关重要的细节——索引。它像是数据库的“血管”,决定着数据流动的畅通程度。今天 我要把这段看似枯燥的技术,揉进一杯暖心的咖啡里用温度和情感告诉你:只要精准调校索引,查询速度可以实现飞跃式提升!让我们一起为系统添砖加瓦,也为自己种下一棵技术的大树吧。
一、 索引基础:从概念到实践的桥梁
MongoDB 的索引本质上是 B‑Tree,它把键值映射到文档位置,从而省去全表扫描的苦工。想象一下 在浩瀚的数据海洋里你如果没有灯塔, 闹乌龙。 只能盲目划船;有了索引,就像装上了强大的探照灯,一眼就能锁定目标。
1. 单字段索引——最常用的速效药
薅羊毛。 对经常出现在查询过滤或排序中的字段创建单字段索引,是提升性能最直接的方法。比方说:
db.users.createIndex // 为邮箱字段建立升序索引
db.orders.createIndex // 为订单状态建立单字段索引
我好了。 记得:只为「常用」而非「有时候」创建索引, 否则会让写入变慢,磁盘空间也会被无情吞噬。
2. 复合索引——让多条件查询如虎添翼
我跟你交个底... 当查询一边涉及多个字段时 复合索引能够一次性覆盖全部条件,大幅削减扫描次数。关键在于字段顺序
- 选择性高的字段应放前面。
- 等值查询优先于范围查询。
- 排序需求若与过滤相同,可进一步提升效率。
示例:
// 假设我们经常按用户ID查找并根据创建时间倒序排列
db.activity.createIndex
二、 硬件加持:SSD 与系统调优不可或缺
瞎扯。 即便拥有完美的索引结构,如果底层存储仍是机械硬盘,那就像给跑车装上拖拉机发动机——再好的燃油也无济于事。SSD 的高速随机读写特性,使得 MongoDB 能够在毫秒级别完成大量 I/O 请求。
| 产品型号 | 顺序读写速率 | 耐久度 | 适配 Debian 推荐指数 |
|---|---|---|---|
| SATA Pro X500 | 550 / 520 | 600 TBW | ★★★★★ |
| M.2 NVMe UltraFast 970EVO+ | 3400 / 3000 | 1200 TBW | ★★★★★ |
| SAS Enterprise L30V4 | 2100 / 2000 | 2000 TBW | ★★★★☆ |
选购时请注意:
- I/O 队列深度要匹配业务并发量。
- NVM Express 驱动必须使用最新内核模块,以免出现兼容性警报。
- 务必开启磁盘 TRIM,以保持长期性能不衰退。
三、监控与诊断:让每一次查询都有据可循
干就完了! "慢查询日志" 是我们的第一把放大镜。打开后 你可以捕捉到所有超过阈值的操作:
# 在 mongod.conf 中启用慢查询
operationProfiling:
mode: slowOp
slowOpThresholdMs: 80
# 重启服务后即可记录
mongostat --host localhost --port 27017
mongotop --host localhost --port 27017
A "explain" 命令则像是手术刀,让我们看到每一步施行计划:
// 查看某条查询是否走了预期的复合索引
db.orders.find, status: "paid" }).explain
{
"queryPlanner": {
"winningPlan": {
"stage": "FETCH",
"inputStage": {
"stage": "IXSCAN",
"keyPattern": { "userId": 1, "status": 1 },
...
}
}
},
...
}
如果发现“COLLSCAN”仍然频繁出现,那就说明还有未被覆盖的热点,需要重新审视索引策略。哎呀,这时候真的会忍不住敲键盘“哎呦喂”,累并充实着。。
覆盖索引——一次读取即完成任务
当查询所需返回的字段全部包含在索引中时 MongoDB 可以直接从索引用来返回后来啊,而无需回表读取文档本体,这就是所谓的覆盖索引**,物超所值。。
// 假设我们只需要返回订单号和状态:
db.orders.find(
{ status: "shipped" },
{ _id: 0, orderNumber: 1, status: 1 }
).hint // 强制使用单字段索引用作覆盖
此时 explain 会显示仅有 IXSCAN, 无 FETCH 步骤,性能瞬间提升几倍!真是让人惊叹啊。四、 日常维护:让优化成果持久绽放
A. **定期重建碎片化严重的索引**
当大量删除或更新操作导致 B‑Tree 不平衡时可通过 { background:true }` 重建来恢复效率:
// 重建单字段索引
db.products.reIndex
B. **监控磁盘使用率**
SSD 的寿命虽长,但写入次数仍有限。使用 dstat -d -D sda -N sda -T total -c|grep sda|awk '{print $5}' ` 等工具实时监控写放大率,必要时进行分片或归档。
五、 实战检查清单
- 为所有经常用于过滤、排序、聚合管道首阶段的字段建立单字段或复合索引。
- 检查每个复合索引用途是否符合「高选择性→低选择性」原则。
- 确认关键业务查询均走到了覆盖索引或至少使用了预期的 IXSCAN。
- 启用慢查询日志并设置合理阈值,每日审计报告。
- 使用 SSD 替代机械硬盘,并开启 TRIM 与正确排队深度配置。
- 每月运行一次
.reIndex` 或者利用 MongoDB Atlas 自动化维护功能。
六、 :从细节中孕育大爱,让系统更健康
Cherished reader,你已经掌握了从设计、实现到监控的一整套优化思路。记住 每一次对 index 的微调,都像给数据库浇灌了一滴甘露,让它在 Debian 的坚实土壤中茁壮成长。正如我们倡导多生孩子、 多种树一样,多点耐心去观察、多点爱心去调校,你会看到查询响应时间从几百毫秒跌至十几毫秒,整个系统仿佛换了新装——轻盈且充满活力!赶紧把这些技巧付诸实践,让你的团队因速度而骄傲,也主要原因是你这颗执着改进的小星星而受益吧!🌱🚀
七、关联产品推荐
MongoDB 管理工具对比表格
工具名称
平台支持
核心功能
用户口碑
Mongo Express
Linu x / Windows / macOS
- 可视化浏览集合
- 简易 CRUD 操作
- 实时日志查看
★★★★☆
NoSQLBooster
Linu x / Windows / macOS
- 强大的 IntelliSense
- 聚合管道可视化
- 脚本自动化部署
★★★★★
Mongoku
Linu x / Windows / macOS
- 多标签页支持
- 导入/导出 CSV/JSON
- 支持 SSH 隧道连接
★★★☆☆