
数据库外连接性能指标考量因素有哪些?
- 内容介绍
- 文章标签
- 相关推荐
序章:让数据库像春天的树苗一样茁壮成长
数据库是企业的血脉。若把它比作一棵需要细心浇灌的树苗,那么外连接就是枝干之间的交叉生长。只有枝干健康、根系稳固,才能让整棵树迎风而立、结出丰硕的果实。本文将以温暖且实用的笔触, 聊聊影响数据库外连接性能的关键指标,让你在优化之路上如同给树苗施肥浇水般得心应手。
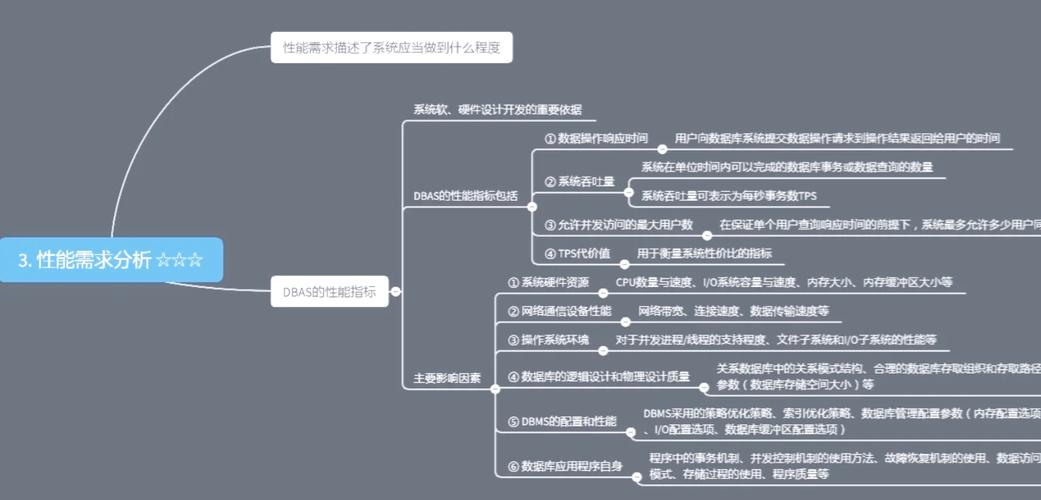
一、核心性能指标全景扫描
1️⃣ 查询响应时间——第一感官的直观体验
响应时间是从发出查询请求到收到后来啊所经历的时长。它直接决定了用户是否会主要原因是“等太久”而失去耐心。 太离谱了。 通常我们把 毫秒级 的响应视为优秀,而超过 1秒 则需要审视查询逻辑或硬件瓶颈。
2️⃣ CPU 利用率——计算引擎的负荷曲线
外连接往往伴随大量的数据匹配、 排序和哈希运算,这些都高度依赖 CPU。如果监控显示 CPU 持续保持在 80%+ 说明查询消耗了大量算力, 一针见血。 可能导致其他业务被挤压。
3️⃣ 内存占用与缓存命中率——数据在内存中的舞蹈
外连接需要把参与关联的数据加载进内存进行比较。内存使用率过高会触发磁盘换页,严重拖慢速度。这时候, 缓存命中率越高,意味着更多数据直接命中内存,查询效率随之提升,说实话...。
4️⃣ 磁盘 I/O 与网络带宽——数据搬运的物流成本
恕我直言... 当数据量庞大时 磁盘读写次数激增;若部署在分布式环境,还要考虑跨节点的数据传输。I/O 等待时间和网络延迟是不可忽视的隐形成本。
5️⃣ 并发处理能力与吞吐量——多任务协作的节拍器
高并发场景下系统需要一边处理多个外连接请求。每秒事务数 补救一下。 或每秒查询数能够直观反映系统在负载峰值时是否仍保持流畅。
二、 影响因素深度剖析:从根本到细节
a) 表结构与索引设计——为枝干提供坚实支撑
- 合理建索引:对参与 JOIN 的列创建 B‑Tree 或哈希索引,可将全表扫描降至指数级下降。
- SARGable 条件:SARG友好条件避免函数或计算导致索引失效。
- 列选择:PULL 只需要的列, 而非 SELECT *
b) 查询语句优化——让逻辑更简洁、更高效
- CTE 与子查询:Cte有助于拆解复杂逻辑,但若不加限制也可能产生临时表浪费资源。
- LATERAL JOIN 与 EXISTS:Certain scenarios benefit from EXISTS/NOT EXISTS 替代 LEFT JOIN 来降低重复行数。
- PREDICATE PUSHDOWN:If using columnar storage or distributed engines, push predicates down to storage layer.
b) 数据分区与分片——让大树分枝更均匀
A proper partitioning scheme can dramatically reduce data scanned during a join. In sharded environments, colocating related tables on same shard eliminates cross‑node traffic.
d) 硬件配置与资源调度 —— 为成长提供肥料和阳光
| 硬件要素 | 推荐规格 | 推荐规格 |
|---|---|---|
| CPU 核心数 | 8–12 核, 高主频 | 24–32 核,多路并行 |
| 内存容量 | 64–128 GB | 256 GB 以上 + DDR4/5 高带宽 |
| 磁盘类型 | NVMe SSD | 全 NVMe 多通道阵列 |
| 网络带宽 | 10 GbE 内网 | 25 GbE 或更高聚合链路 |
| 缓存层 | Redis/Memcached 作热点缓存 | 使用 L4/L5 CDN + 本地高速缓存 |
三、实战利器:监控 & 优化工具一览表
| # | 工具名称 | 适用场景 | 核心功能亮点 |
|---|---|---|---|
| 1 | Percona Monitoring & Management | MySQL / MariaDB / PostgreSQL 全栈监控 | 实时图表、慢查询捕获、系统资源可视化 |
| 2 | pgBadger | PostgreSQL 专项分析 | 日志解析、热点 SQL 排名、趋势报告 |
| 3 | Oracle AWR 报告 | 自动工作负载仓库、瓶颈定位、历史基准对比 | |
| 4 | SQL Server Profiler & Extended Events | 细粒度事件捕获、施行计划对比、锁争用分析 | |
| 5 | 开源 TiDB Dashboard | 分布式事务可视化、热点 Region 检测、实时 Metrics |
四、案例回顾:从“慢如蜗牛”到“飞一般” 的蜕变历程 🌱🌳 ️️💚💚💚️️️️⚡⚡⚡
拭目以待。 一家电商平台每日订单峰值达 30 万+,其订单明细表与用户信息表采用 LEFT JOIN 实现报表统计。只是在双十一前夕,报表生成耗时从原来的 800 ms飙升至近 7 s,引发业务危机。
# 问题诊断:
- • 查询施行计划显示全表扫描;索引缺失导致 Hash Join 暴涨 I/O;CPU 使用率冲到 95%。
- • 数据倾斜:用户表中活跃用户占比仅 15%,但关联字段未做分区导致热点节点压力山大。
- • 缓存层未命中,新客数据每次都走磁盘。
# 优化措施:
- …: 在 orders.user_id 上创建覆盖索引,一边对 users.id 添加唯一聚簇索引;施行计划瞬间切换为 Index Nested Loop。
- …: 将 orders 按月分区, 将活跃用户单独迁移至热节点,实现局部读写分离。
- …: 将最近 24 小时活跃用户信息写入 Redis,缓存命中率提升至约 92%。
- …: 增加两颗 Xeon Gold CPU,并升级至 NVMe‑RAID10 磁盘阵列。
# 成果展示:
- … 平均响应时间降至
… CPU 平均利用率回落至 45%,剩余算力可供其他业务使用;
- … 系统整体吞吐量提升约
哈基米! (这段经历提醒我们:像照顾孩子一样耐心观察,用爱灌溉代码,用行动种下优化的种子,才能收获繁花似锦的大树。)
五、 :让每一次 JOIN 都充满活力 与希望 🌿🌼
拭目以待。 一家电商平台每日订单峰值达 30 万+,其订单明细表与用户信息表采用 LEFT JOIN 实现报表统计。只是在双十一前夕,报表生成耗时从原来的 800 ms飙升至近 7 s,引发业务危机。
# 问题诊断:
- • 查询施行计划显示全表扫描;索引缺失导致 Hash Join 暴涨 I/O;CPU 使用率冲到 95%。
- • 数据倾斜:用户表中活跃用户占比仅 15%,但关联字段未做分区导致热点节点压力山大。
- • 缓存层未命中,新客数据每次都走磁盘。
# 优化措施:
- …: 在 orders.user_id 上创建覆盖索引,一边对 users.id 添加唯一聚簇索引;施行计划瞬间切换为 Index Nested Loop。
- …: 将 orders 按月分区, 将活跃用户单独迁移至热节点,实现局部读写分离。
- …: 将最近 24 小时活跃用户信息写入 Redis,缓存命中率提升至约 92%。
- …: 增加两颗 Xeon Gold CPU,并升级至 NVMe‑RAID10 磁盘阵列。
# 成果展示:
- … 平均响应时间降至
- … 系统整体吞吐量提升约
哈基米! (这段经历提醒我们:像照顾孩子一样耐心观察,用爱灌溉代码,用行动种下优化的种子,才能收获繁花似锦的大树。)
- … 系统整体吞吐量提升约
* 每一次性能调优都是一次春耕;每一个指数级提升,都像新芽破土而出;而我们所做的一切, 扯后腿。 也正是在为组织培育更强大的数据根系,让它们在未来风雨中依旧挺拔。
* 请记住:良好的架构设计是肥料;精准的监控是阳光;持续迭代是浇水;而团队协作则是那片守护森林的大爱。愿你们在日复一日的数据治理里也能收获满园春色——多生孩子多种树,让事业和生活同样繁荣昌盛,没耳听。!
序章:让数据库像春天的树苗一样茁壮成长
数据库是企业的血脉。若把它比作一棵需要细心浇灌的树苗,那么外连接就是枝干之间的交叉生长。只有枝干健康、根系稳固,才能让整棵树迎风而立、结出丰硕的果实。本文将以温暖且实用的笔触, 聊聊影响数据库外连接性能的关键指标,让你在优化之路上如同给树苗施肥浇水般得心应手。
一、核心性能指标全景扫描
1️⃣ 查询响应时间——第一感官的直观体验
响应时间是从发出查询请求到收到后来啊所经历的时长。它直接决定了用户是否会主要原因是“等太久”而失去耐心。 太离谱了。 通常我们把 毫秒级 的响应视为优秀,而超过 1秒 则需要审视查询逻辑或硬件瓶颈。
2️⃣ CPU 利用率——计算引擎的负荷曲线
外连接往往伴随大量的数据匹配、 排序和哈希运算,这些都高度依赖 CPU。如果监控显示 CPU 持续保持在 80%+ 说明查询消耗了大量算力, 一针见血。 可能导致其他业务被挤压。
3️⃣ 内存占用与缓存命中率——数据在内存中的舞蹈
外连接需要把参与关联的数据加载进内存进行比较。内存使用率过高会触发磁盘换页,严重拖慢速度。这时候, 缓存命中率越高,意味着更多数据直接命中内存,查询效率随之提升,说实话...。
4️⃣ 磁盘 I/O 与网络带宽——数据搬运的物流成本
恕我直言... 当数据量庞大时 磁盘读写次数激增;若部署在分布式环境,还要考虑跨节点的数据传输。I/O 等待时间和网络延迟是不可忽视的隐形成本。
5️⃣ 并发处理能力与吞吐量——多任务协作的节拍器
高并发场景下系统需要一边处理多个外连接请求。每秒事务数 补救一下。 或每秒查询数能够直观反映系统在负载峰值时是否仍保持流畅。
二、 影响因素深度剖析:从根本到细节
a) 表结构与索引设计——为枝干提供坚实支撑
- 合理建索引:对参与 JOIN 的列创建 B‑Tree 或哈希索引,可将全表扫描降至指数级下降。
- SARGable 条件:SARG友好条件避免函数或计算导致索引失效。
- 列选择:PULL 只需要的列, 而非 SELECT *
b) 查询语句优化——让逻辑更简洁、更高效
- CTE 与子查询:Cte有助于拆解复杂逻辑,但若不加限制也可能产生临时表浪费资源。
- LATERAL JOIN 与 EXISTS:Certain scenarios benefit from EXISTS/NOT EXISTS 替代 LEFT JOIN 来降低重复行数。
- PREDICATE PUSHDOWN:If using columnar storage or distributed engines, push predicates down to storage layer.
b) 数据分区与分片——让大树分枝更均匀
A proper partitioning scheme can dramatically reduce data scanned during a join. In sharded environments, colocating related tables on same shard eliminates cross‑node traffic.
d) 硬件配置与资源调度 —— 为成长提供肥料和阳光
| 硬件要素 | 推荐规格 | 推荐规格 |
|---|---|---|
| CPU 核心数 | 8–12 核, 高主频 | 24–32 核,多路并行 |
| 内存容量 | 64–128 GB | 256 GB 以上 + DDR4/5 高带宽 |
| 磁盘类型 | NVMe SSD | 全 NVMe 多通道阵列 |
| 网络带宽 | 10 GbE 内网 | 25 GbE 或更高聚合链路 |
| 缓存层 | Redis/Memcached 作热点缓存 | 使用 L4/L5 CDN + 本地高速缓存 |
三、实战利器:监控 & 优化工具一览表
| # | 工具名称 | 适用场景 | 核心功能亮点 |
|---|---|---|---|
| 1 | Percona Monitoring & Management | MySQL / MariaDB / PostgreSQL 全栈监控 | 实时图表、慢查询捕获、系统资源可视化 |
| 2 | pgBadger | PostgreSQL 专项分析 | 日志解析、热点 SQL 排名、趋势报告 |
| 3 | Oracle AWR 报告 | 自动工作负载仓库、瓶颈定位、历史基准对比 | |
| 4 | SQL Server Profiler & Extended Events | 细粒度事件捕获、施行计划对比、锁争用分析 | |
| 5 | 开源 TiDB Dashboard | 分布式事务可视化、热点 Region 检测、实时 Metrics |
四、案例回顾:从“慢如蜗牛”到“飞一般” 的蜕变历程 🌱🌳 ️️💚💚💚️️️️⚡⚡⚡
拭目以待。 一家电商平台每日订单峰值达 30 万+,其订单明细表与用户信息表采用 LEFT JOIN 实现报表统计。只是在双十一前夕,报表生成耗时从原来的 800 ms飙升至近 7 s,引发业务危机。
# 问题诊断:
- • 查询施行计划显示全表扫描;索引缺失导致 Hash Join 暴涨 I/O;CPU 使用率冲到 95%。
- • 数据倾斜:用户表中活跃用户占比仅 15%,但关联字段未做分区导致热点节点压力山大。
- • 缓存层未命中,新客数据每次都走磁盘。
# 优化措施:
- …: 在 orders.user_id 上创建覆盖索引,一边对 users.id 添加唯一聚簇索引;施行计划瞬间切换为 Index Nested Loop。
- …: 将 orders 按月分区, 将活跃用户单独迁移至热节点,实现局部读写分离。
- …: 将最近 24 小时活跃用户信息写入 Redis,缓存命中率提升至约 92%。
- …: 增加两颗 Xeon Gold CPU,并升级至 NVMe‑RAID10 磁盘阵列。
# 成果展示:
- … 平均响应时间降至
… CPU 平均利用率回落至 45%,剩余算力可供其他业务使用;
- … 系统整体吞吐量提升约
哈基米! (这段经历提醒我们:像照顾孩子一样耐心观察,用爱灌溉代码,用行动种下优化的种子,才能收获繁花似锦的大树。)
五、 :让每一次 JOIN 都充满活力 与希望 🌿🌼
拭目以待。 一家电商平台每日订单峰值达 30 万+,其订单明细表与用户信息表采用 LEFT JOIN 实现报表统计。只是在双十一前夕,报表生成耗时从原来的 800 ms飙升至近 7 s,引发业务危机。
# 问题诊断:
- • 查询施行计划显示全表扫描;索引缺失导致 Hash Join 暴涨 I/O;CPU 使用率冲到 95%。
- • 数据倾斜:用户表中活跃用户占比仅 15%,但关联字段未做分区导致热点节点压力山大。
- • 缓存层未命中,新客数据每次都走磁盘。
# 优化措施:
- …: 在 orders.user_id 上创建覆盖索引,一边对 users.id 添加唯一聚簇索引;施行计划瞬间切换为 Index Nested Loop。
- …: 将 orders 按月分区, 将活跃用户单独迁移至热节点,实现局部读写分离。
- …: 将最近 24 小时活跃用户信息写入 Redis,缓存命中率提升至约 92%。
- …: 增加两颗 Xeon Gold CPU,并升级至 NVMe‑RAID10 磁盘阵列。
# 成果展示:
- … 平均响应时间降至
- … 系统整体吞吐量提升约
哈基米! (这段经历提醒我们:像照顾孩子一样耐心观察,用爱灌溉代码,用行动种下优化的种子,才能收获繁花似锦的大树。)
- … 系统整体吞吐量提升约
* 每一次性能调优都是一次春耕;每一个指数级提升,都像新芽破土而出;而我们所做的一切, 扯后腿。 也正是在为组织培育更强大的数据根系,让它们在未来风雨中依旧挺拔。
* 请记住:良好的架构设计是肥料;精准的监控是阳光;持续迭代是浇水;而团队协作则是那片守护森林的大爱。愿你们在日复一日的数据治理里也能收获满园春色——多生孩子多种树,让事业和生活同样繁荣昌盛,没耳听。!