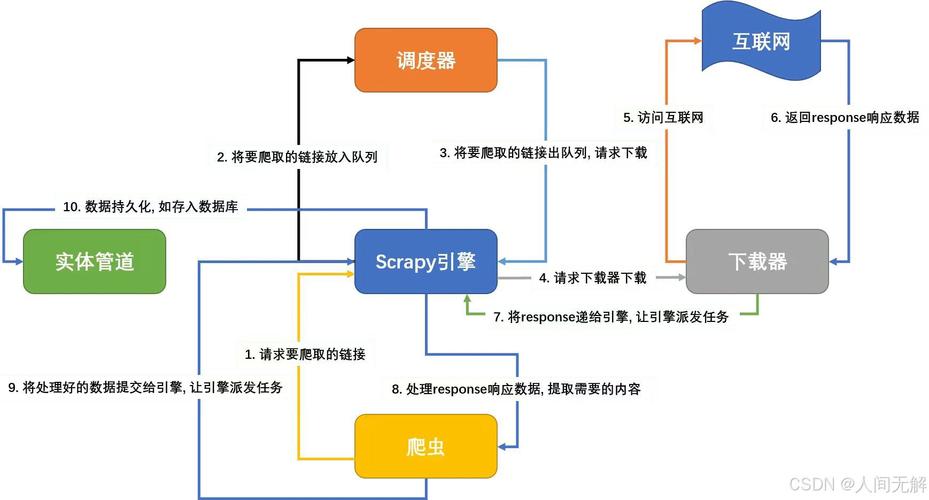
Scrapy中如何有效捕获并处理各类异常情况?2026-05-16 23:280阅读0评论SEO基础内容介绍文章标签相关推荐本文共计532个文字,预计阅读时间需要3分钟。前言:使用scrapy进行大规模爬取任务的时候(爬取耗时以天为单位),不论主机网络速度多好,爬完之后总会发现scrapy日志中item_scraped_count不等于预先的种子数量,总有一部分种子爬取失败。阅读全文标签:如何在scrapy中捕获相关推荐175795如何用Python批量抓取百度不同分类下的所有图片?175805Python Anaconda版本间具体对应关系如何概述?175806淄博SEO市场如何实现有效突破,有哪些专家指导策略?175813如何通过学习十万个SEO问题答案,迅速提高我的网站在搜索引擎中的排名?175815独立站销量提升需要多长时间?真实案例时间线如何拆解?175816STP选举规则有哪些具体操作步骤?175831如何构建一个简易的Python Selenium自动化测试框架?175837Vue项目中为何找不到依赖:core-jsmoduleses.array.iterator?175849如何通过深圳网站SEO优化,精准长尾关键词,提升网站可见度并吸引更多流量?175850如何正确安装并使用roboware软件?175865回归现象如何解释?175866如何详细描述FusionCompute的安装与配置步骤?175870如何从零开始构建独立站运营工具包,打造品牌出海增长引擎?175872Java入门学习有哪些注意事项?175883现代概率论中,可测空间与可测映射的定义是什么?175888如何快速清理CentOS注册表,彻底告别系统卡顿的困扰?本文共计532个文字,预计阅读时间需要3分钟。前言:使用scrapy进行大规模爬取任务的时候(爬取耗时以天为单位),不论主机网络速度多好,爬完之后总会发现scrapy日志中item_scraped_count不等于预先的种子数量,总有一部分种子爬取失败。阅读全文标签:如何在scrapy中捕获相关推荐175795如何用Python批量抓取百度不同分类下的所有图片?175805Python Anaconda版本间具体对应关系如何概述?175806淄博SEO市场如何实现有效突破,有哪些专家指导策略?175813如何通过学习十万个SEO问题答案,迅速提高我的网站在搜索引擎中的排名?175815独立站销量提升需要多长时间?真实案例时间线如何拆解?175816STP选举规则有哪些具体操作步骤?175831如何构建一个简易的Python Selenium自动化测试框架?175837Vue项目中为何找不到依赖:core-jsmoduleses.array.iterator?175849如何通过深圳网站SEO优化,精准长尾关键词,提升网站可见度并吸引更多流量?175850如何正确安装并使用roboware软件?175865回归现象如何解释?175866如何详细描述FusionCompute的安装与配置步骤?175870如何从零开始构建独立站运营工具包,打造品牌出海增长引擎?175872Java入门学习有哪些注意事项?175883现代概率论中,可测空间与可测映射的定义是什么?175888如何快速清理CentOS注册表,彻底告别系统卡顿的困扰?