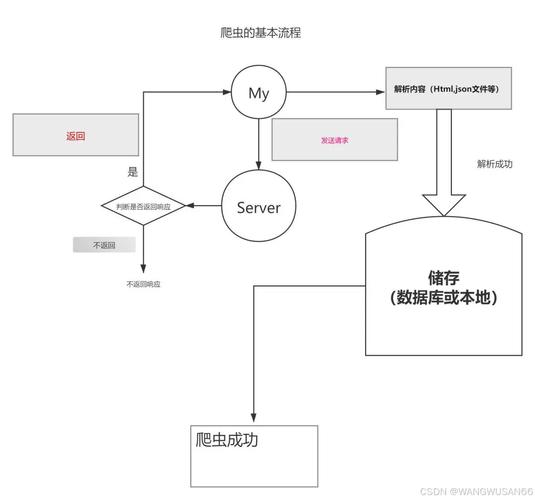
如何通过Python爬虫技术抓取并改写文章内容为长尾关键词?2026-04-19 23:260阅读0评论SEO资讯内容介绍文章标签相关推荐本文共计675个文字,预计阅读时间需要3分钟。根据规则,以下是对原文的简化原则上禁止非人浏览访问,普通爬虫无法爬取文章,需模拟人为浏览器访问。 使用方法:输入带文章链接的文本,自动生成命名的HTML文件。 原则上不让非人浏览访问,正常爬虫无法从这里爬取文章,需要进行模拟人为浏览器访问。阅读全文标签:Python爬虫文章抓取原则上相关推荐108872怀化SEO优化,如何内外兼修提升网站排名?108879如何用Pandas实现类似MySQL日期函数的功能?108880如何确保在Python升级pip过程中遇到失败时,能够有效处理并成功完成升级?108882PyTorch LSTM如何实现单变量时间序列预测?108886如何将pandas.DataFrame的for循环迭代改写为更高效的长尾词?108887如何用Pandas实现类似MySQL窗口函数的复杂数据处理操作?108892分水岭算法在图像分割中的应用,如何实现长尾词效果?108898如何快速查询网站排名,有没有什么神器推荐?108899Python的random函数实例究竟包含哪些详尽的用法和特性?108902如何安装pygraphviz以实现复杂网络图绘制?108916如何解决python2.7安装opencv-python速度慢且频繁失败的问题?108920如何将Numpy数值积分的实现转化为一个长尾词?108921如何高效运用scipy的dok_array稀疏数组处理大规模数据结构?108923如何详细配置Anaconda和Pycharm,实现高效编程环境搭建?108926如何通过网络营销和多渠道拓展,实现创意无限的策略?108935Django数据库遇到1045、1049、2003错误怎么办?本文共计675个文字,预计阅读时间需要3分钟。根据规则,以下是对原文的简化原则上禁止非人浏览访问,普通爬虫无法爬取文章,需模拟人为浏览器访问。 使用方法:输入带文章链接的文本,自动生成命名的HTML文件。 原则上不让非人浏览访问,正常爬虫无法从这里爬取文章,需要进行模拟人为浏览器访问。阅读全文标签:Python爬虫文章抓取原则上相关推荐108872怀化SEO优化,如何内外兼修提升网站排名?108879如何用Pandas实现类似MySQL日期函数的功能?108880如何确保在Python升级pip过程中遇到失败时,能够有效处理并成功完成升级?108882PyTorch LSTM如何实现单变量时间序列预测?108886如何将pandas.DataFrame的for循环迭代改写为更高效的长尾词?108887如何用Pandas实现类似MySQL窗口函数的复杂数据处理操作?108892分水岭算法在图像分割中的应用,如何实现长尾词效果?108898如何快速查询网站排名,有没有什么神器推荐?108899Python的random函数实例究竟包含哪些详尽的用法和特性?108902如何安装pygraphviz以实现复杂网络图绘制?108916如何解决python2.7安装opencv-python速度慢且频繁失败的问题?108920如何将Numpy数值积分的实现转化为一个长尾词?108921如何高效运用scipy的dok_array稀疏数组处理大规模数据结构?108923如何详细配置Anaconda和Pycharm,实现高效编程环境搭建?108926如何通过网络营销和多渠道拓展,实现创意无限的策略?108935Django数据库遇到1045、1049、2003错误怎么办?